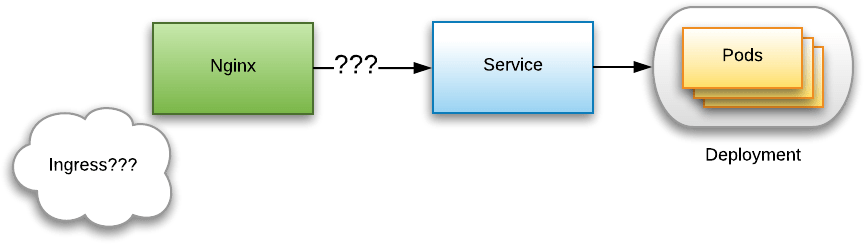
The development and deployment of modern apps is very different from how it used to be. Networked applications are now very common. Development at scale is now common: hundreds of developers working on a system, which may be split into many microservices. Deployment at scale is now also common: apps serving millions of users. Various practices emerged, or became popular, to deal with these new challenges. I’ve learned many practices over the past decade, but resources that describe these practices appear to be scattered. This post is an attempt to inventorize the various practices that are used for the development, deployment and management of modern apps.